Mybatis是如何进行分页的?
Mybatis是如何进行分页的?
逻辑分页
先把所有数据查询到内存中,通过具体的业务逻辑筛选出合适的数据
物理分页
数据库的分页功能,比如mysql的limit,oracle的rownum
mybatis共有三种实现方式
直接在mybatis的mapper文件中去写分页的sql
这种方式比较灵活,实现简单
通过RowBounds实现逻辑分页
这种方式不适用于数据量较大的场景,有可能会频繁的访问数据库,给数据库增加比较大的压力
一次性加载所有符合查询条件的数据到内存中,根据分页参数的值在内存中实现分页。
在数据量比较大的时候,jdbc会进行优化:不会一次性去把所有的数据查询存储在ResultSet中,而是先加载一部分数据,在根据需求去数据库中滚动加载后续的数据。
通过分页Interceptor拦截器实现
可以提供统一的处理机制,不需要单独的维护分页相关的功能
拦截需要分页的select语句,在select语句中去动态的拼接分页的关键字,从而去实现分页的查询。
常用的pageHelper,mybatis-plus的分页都是基于Interceptor的扩展
实现代码示例
demo地址:trygo/page_demo (gitee.com)
创建一个项目,引入mybatis连接数据库的相关依赖
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19<!-- mybatis依赖 -->
<dependency>
<groupId>org.mybatis.spring.boot</groupId>
<artifactId>mybatis-spring-boot-starter</artifactId>
<version>2.3.1</version>
</dependency>
<!-- 链接数据库的驱动 -->
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
</dependency>
<!-- SpringBoot整合Druid -->
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>druid-spring-boot-starter</artifactId>
<version>1.1.23</version>
</dependency>配置项目的数据源信息
在application.yml文件中配置
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74server:
port: 8080
spring:
datasource:
# 配置数据源类型为DruidDataSource
type: com.alibaba.druid.pool.DruidDataSource
druid:
driver-class-name: com.mysql.cj.jdbc.Driver
url: jdbc:mysql://localhost:3306/page_demo?useSSL=false&serverTimezone=GMT%2B8
username: root
password: 123456
# 连接池配置:大小,最小,最大
initial-size: 5
min-idle: 5
max-active: 20
# 连接等待超时时间
max-wait: 30000
# 配置检测可以关闭的空闲连接,间隔时间
time-between-eviction-runs-millis: 60000
# 配置连接在池中的最小生存时间
min-evictable-idle-time-millis: 300000
# 检测连接是否有,有效得select语句
validation-query: select '1' from dual
# 申请连接的时候检测,如果空闲时间大于time-between-eviction-runs-millis,执行validationQuery检测连接是否有效,建议配置为true,不影响性能,并且保证安全性。
test-while-idle: true
# 申请连接时执行validationQuery检测连接是否有效,建议设置为false,不然会会降低性能
test-on-borrow: false
# 归还连接时执行validationQuery检测连接是否有效,建议设置为false,不然会会降低性能
test-on-return: false
# 是否缓存preparedStatement,也就是PSCache 官方建议MySQL下建议关闭 个人建议如果想用SQL防火墙 建议打开
# 打开PSCache,并且指定每个连接上PSCache的大小
pool-prepared-statements: false
max-open-prepared-statements: 20
max-pool-prepared-statement-per-connection-size: 20
# 配置监控统计拦截的filters, 去掉后监控界面sql无法统计, 'wall'用于防火墙防御sql注入,stat监控统计,logback日志
filters: stat,wall
# Spring监控AOP切入点,如x.y.z.service.*,配置多个英文逗号分隔
#aop-patterns: com.springboot.servie.*
# lowSqlMillis用来配置SQL慢的标准,执行时间超过slowSqlMillis的就是慢
connectionProperties: druid.stat.mergeSql=true;druid.stat.slowSqlMillis=500
# WebStatFilter监控配置
web-stat-filter:
enabled: true
# 添加过滤规则:那些访问拦截统计
url-pattern: /*
# 忽略过滤的格式:哪些不拦截,不统计
exclusions: '*.js,*.gif,*.jpg,*.png,*.css,*.ico,/druid/*'
# StatViewServlet配置(Druid监控后台的Servlet映射配置,因为SpringBoot项目没有web.xml所在在这里使用配置文件设置)
stat-view-servlet:
enabled: true
# 配置Servlet的访问路径:访问路径为/druid/**时,跳转到StatViewServlet,会自动转到Druid监控后台
url-pattern: /druid/*
# 是否能够重置数据
reset-enable: false
# 设置监控后台的访问账户及密码
login-username: trygo
login-password: trygo
# IP白名单:允许哪些主机访问,默认为“”任何主机
# allow: 127.0.0.1
# IP黑名单:禁止IP访问,(共同存在时,deny优先于allow)
# deny: 192.168.1.218
# 配置StatFilter
filter:
stat:
log-slow-sql: true数据库导入测试数据
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25create table user
(
user_id varchar(32) not null comment '用户主键id'
primary key,
username varchar(32) null comment '昵称',
gender tinyint null comment '性别',
age int null comment '年龄'
)
comment '用户表';
insert into user
values (replace(uuid(), '-', ''), '张三', 1, 15),
(replace(uuid(), '-', ''), '李四', 1, 16),
(replace(uuid(), '-', ''), '王五', 1, 18),
(replace(uuid(), '-', ''), '聂小倩', 0, 200),
(replace(uuid(), '-', ''), '宁采臣', 1, 42),
(replace(uuid(), '-', ''), '令狐冲', 1, 25),
(replace(uuid(), '-', ''), '杨过', 1, 18),
(replace(uuid(), '-', ''), '幼年杨过', 1, 8),
(replace(uuid(), '-', ''), '李莫愁', 0, 21),
(replace(uuid(), '-', ''), '海波东', 1, 35),
(replace(uuid(), '-', ''), '萧炎', 1, 18),
(replace(uuid(), '-', ''), '小医仙', 0, 17),
(replace(uuid(), '-', ''), '萧熏儿', 0, 25),
(replace(uuid(), '-', ''), '美杜莎', 0, 10000);创建实体类和相关service,mapper等相关代码
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57public class User {
private String userId;
private String username;
private Integer gender;
private Integer age;
public String getUserId() {
return userId;
}
public void setUserId(String userId) {
this.userId = userId;
}
public String getUsername() {
return username;
}
public void setUsername(String username) {
this.username = username;
}
public Integer getGender() {
return gender;
}
public void setGender(Integer gender) {
this.gender = gender;
}
public Integer getAge() {
return age;
}
public void setAge(Integer age) {
this.age = age;
}
public String toString() {
final StringBuilder sb = new StringBuilder("User").append('[')
.append("userId=")
.append(userId)
.append(",username=")
.append(username)
.append(",gender=")
.append(gender)
.append(",age=")
.append(age)
.append(']');
return sb.toString();
}
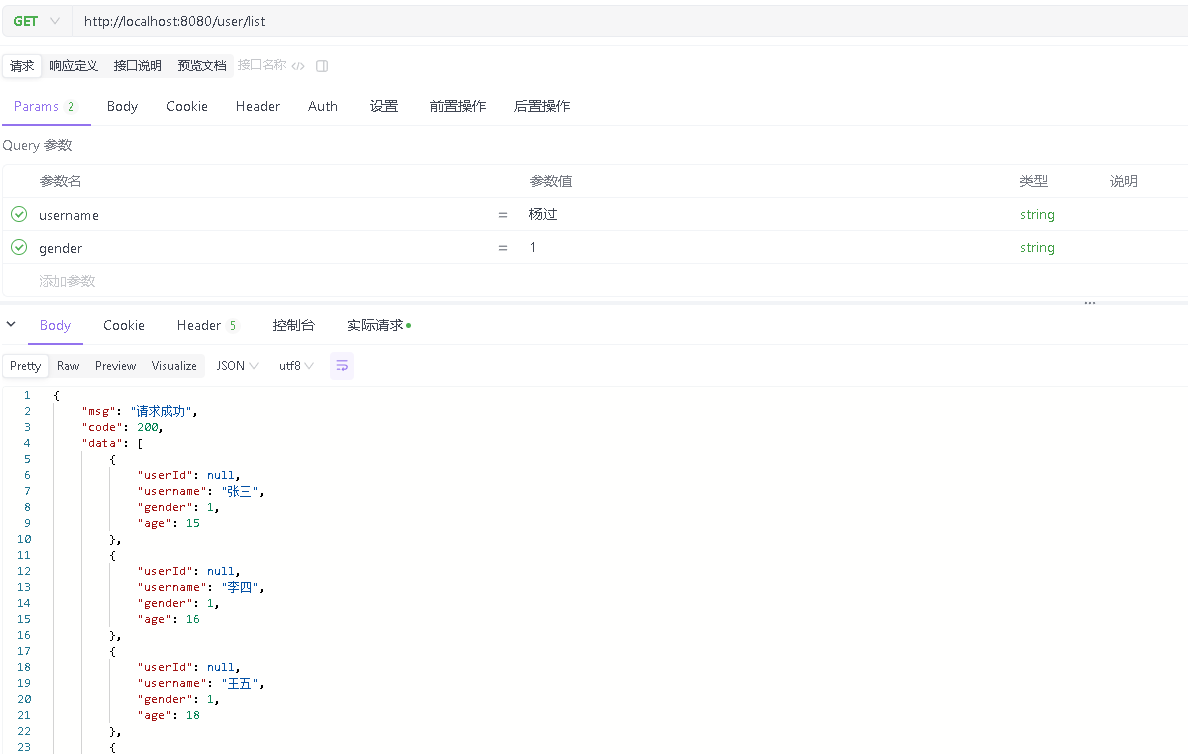
}调用接口测试不分页情况下是否正常运行
接口运行正常
实现具体的分页逻辑
引入pageHelper依赖
1
2
3
4
5<dependency>
<groupId>com.github.pagehelper</groupId>
<artifactId>pagehelper-spring-boot-starter</artifactId>
<version>1.4.7</version>
</dependency>配置pageHelper
1
2
3
4
5
6mybatis:
page-helper:
helper-dialect: mysql
reasonable: true
support-methods-arguments: true
params: count=countSql分页逻辑编写
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
public HashMap<String, Object> page(User user){
HashMap<String, Object> res = new HashMap<>();
try {
PageHelper.startPage(user.getPageNo(), user.getPageSize());
List<User> userList = userService.getUserList(user);
PageInfo<User> userPageInfo = new PageInfo<>(userList);
res.put("data", userPageInfo);
res.put("msg","请求成功");
res.put("code",200);
} catch (Exception e) {
e.printStackTrace();
res.put("msg","请求失败");
res.put("code",500);
}
return res;
}


